
Когда меня впервые посетила мысль написать статью о связке Excel + SEO, передо мной встала дилемма: о чём писать, чтобы не прослыть «капитаном Очевидность» и в то же время не углубляться в нюансы специфических инструментов, которые многие SEO-специалисты не используют в принципе. Я решил пойти самым верным путем: описать методы решения с помощью Excel тех SEO-задач, которые я сам решаю ежедневно.
Но сперва — несколько слов о том, почему важно использовать правильные инструменты для решения тех или иных задач. Первое, что бросается в глаза, когда ты заходишь на профильный форум или SEO-блог — проблема низкой технической подкованности молодых специалистов. Такие распространённые в практическом SEO проблемы как сортировка и анализ массивов данных, различные варианты работы со строками, агрегация данных и, наоборот, их разбитие — всё это большинство веб-мастеров выполняет вручную, тратя огромное количество времени на монотонные, однообразные и легко автоматизируемые задачи.
Одни пытаются найти готовое узкофункциональное решение для своей проблемы: «Помогите найти программу для условного сложения значений строк», «Подскажите программу чтобы выделить домен со списка» и т.д. Другие пишут скрипты-решения для всех проблем, с которыми сталкиваются. Третьи используют дорогие профессиональные программы (Deductor для формирования срезов данных, TextPipe для работы со строками и т.п.) для довольно-таки базовых операций.
А ведь большинство наших проблем решает Microsoft Excel (как и Google SpreadSheet, и LibreOffice). Далее — яркие тому доказательства.
Функция № 1: ДЛСТР (англ LEN)
Применяется для определения длины текстового содержимого ячейки (или текста, заданного в формуле). Применений, как вы понимаете, масса. Например, измерение длины анкоров или мета-тегов на предмет превышения лимита (для примера возьмём 70 знаков для title)

Добавим условное форматирование для наглядности:


Строки с длиной меньше допустимого значения выделяем одним цветом, больше — другим.


И получаем:

Не очень художественно, зато наглядно. Особенно когда дело касается нескольких сотен/тысяч мета-тегов. По такому же принципу можно добавлять новые правила для параметров description.
Функция № 2: СЖПРОБЕЛЫ (TRIM)
Удаляет все пробелы, кроме одинарных между словами из содержимого ячейки или заданного фрагмента текста.
На практике функция полезна, когда при копировании всего массива текста появляются пробелы до/после/между слов, создающие проблемы при дальнейшей обработке.
Функции № 3: ПРОПИСН (UPPER), СТРОЧН (LOWER)
Трансформирует содержимое строки (или заданного фрагмента) в прописные или строчные буквы.
Функция № 4: ПРОПНАЧ (PROPER)
Преобразует первые буквы каждого слова в строке в прописные.
Забавно, изначально я не хотел добавлять эту функцию. Казалось бы, кому нужно трансформировать первую букву каждого слова? А параллельно с написанием статьи возникла необходимость проверить частотность группы ключей, содержащих названия компаний.
Как известно, при проверке основными сервисами (как следствие — и программами) все буквы запроса приводятся в строчный вид. Итог: таблица на несколько тысяч строк вида ЗАПРОС + КОМПАНИЯ, где название компании приведено с маленькой буквы. Для дальнейшего использования было необходимо привести всё в человеческий вид.
Выход:
-
Расщепил массив по 2-м столбцам (запрос и название) с помощью функции Данные > Текст по столбцам.
-
Применил функцию ПРОПНАЧ к столбцу с названиями компаний.
-
Произвёл сцепку с первым столбцом.
Данное решение проблемы не единственное из возможных, но точно самое простое.
Функция № 5: СЦЕПИТЬ (текст1;текст2;текст3…) (англ. CONCATENATE)
По-моему, это наиболее полезная в практическом SEO функция. СЦЕПИТЬ позволяет объединить содержимое отдельных текстовых блоков в одну строку. Это может быть как простая сцепка 2-х ячеек, так и более сложный вариант с подставлением текстовых блоков непосредственно в формулу.
Пример: допустим, вам нужно отправить ссылки с 500 не совсем качественных доменов в инструмент Disavow Links. Синтаксис инструмента предполагает формат вида domain:ваш_домен.com.ua. Что делать? Прописывать все 500 строк руками? Конечно же, нет. Всё, что вам нужно — это написать:
|
1 |
«]=СЦЕПИТЬ(«domain:»;адрес_ячейки) |
А затем растянуть формулу на весь столбец.

В подобных простых случаях можно использовать альтернативный вариант написания формулы, используя амперсанд “&”
Рассмотрим на том же примере
|
1 |
«]=»domain:»&адрес_ячейки |
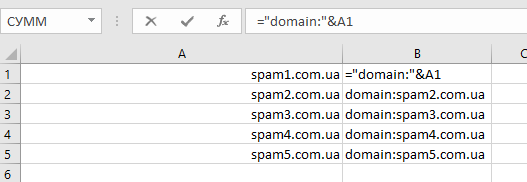
Еще один пример функции СЦЕПИТЬ: у вас есть столбец с URL и столбец с анкорами. Нам нужно сформировать полноценную ссылку следующего вида:
|
1 |
«]<a href=»URL»>анкор</a> |
Это несложно, однако тут есть свои нюансы. Заключаются они в использовании кавычек в текстовом блоке, предшествующем ссылке (и в блоке, идущем сразу за ней). Формула из предыдущего примера не сработает из-за путаницы в одинарных/двойных кавычках.
Неправильно:
|
1 |
«]=СЦЕПИТЬ(«<a href=»»;адрес_ячейки_с_URL;»»>»;адрес_ячейки_анкора;»</a>») |
Варианты решения
1. Несерьезный (отсутствует профессиональный вызов)
Делаем два дополнительных столбца (или ячейки) с данными (см. скриншот ниже):
|
1 2 |
«]<a href=» «></a> |
Вместо первого текстового блока в формуле используем ссылку на первую ячейку, вместо второго — на вторую. В результате получаем:
|
1 |
«]=СЦЕПИТЬ(адрес_ячейки_с_началом;адрес_ячейки_с_URL;адрес_замыкающей ячейки;адрес_ячейки_анкора;»») |

В случае, если вы указывали конкретные ячейки, а не столбцы, не забудьте задать абсолютные адреса:
|
1 |
«]$A$1 |

2. Серьезные (присутствует профессиональный вызов)
2.1 Используем одинарные кавычки
Пишем:
|
1 |
«]=СЦЕПИТЬ(«<a href=’»;адрес_ячейки_с_URL;»’>»;адрес_ячейки_анкора;»</a>») |

Хотя синтаксис ссылок с одинарными кавычками и является валидным, его применение не совсем канонично.
2.2 Используем символ кавычек (chr(34), символ(34))
У двойных кавычек есть цифровой код, а значит, мы можем вывести их с помощью функции chr (в русской версии «символ»).
|
1 |
«]=СЦЕПИТЬ(«<a href=»;символ(34);адрес_ячейки_с_URL;символ(34);»>»;адрес_ячейки_анкора;»</a>») |

Функция № 6: СЧЁТЕСЛИ (диапазон;критерий) (англ. COUNTIF)
Подсчитывает количество ячеек внутри диапазона, удовлетворяющих заданному критерию. Например, вы хотите поверхностно оценить разбавленность анкорного листа сайта URL’ами. Чтобы никого не обижать, возьмём не реальный анкор лист, а выдуманный. Например:

Чтобы прикинуть процент URL-разбавки анкор-листа, посчитаем все вхождения домена нашего сайта (а именно domen.ru) в анкоры. Для этого введем формулу:
|
1 |
«]СЧЁТЕСЛИ(A1:A9;»domen.ru») |

Странно, показывает ноль. Хоть вроде бы вхождение домена в анкорах встречается. Дело в том, что, в отличие от функции ПОИСК (о ней — далее), критерий для СЧЁТЕСЛИ необходимо задавать явно и чётко. В нашем случае в списке нет анкора domen.ru. Для ослабления критериев используется либо звёздочка (любое количество символов), либо знаки вопроса (одна произвольная буква). Для наших целей больше подойдёт звёздочка (она же «астериск»).
|
1 |
«]=СЧЁТЕСЛИ(A1:A9;»*domen.ru*») |

Получилось! Ну, и раз уж мы нашли этот показатель, заодно можем посчитать и относительный вес анкоров с вхождением URL по отношению к общему кол-ву анкоров.
|
1 |
«]=СЧЁТЕСЛИ(A1:A9;»*domen.ru*»)/СЧЁТЗ(A1:A9) |

Внимательный читатель, конечно, заметит, что функция СЧЁТЗ считает только непустые ячейки. В случае выгрузки с сервиса анализа беклинков и большого анкор-листа, полученный нами результат будет некорректным. К счастью, в Excel также есть функция подсчёта и пустых ячеек в диапазоне, носящая красивое название СЧИТАТЬПУСТОТЫ (англ. COUNTA).
Итого, наш финальный вариант:
|
1 |
«]=СЧЁТЕСЛИ(A1:A9;»*domen.ru*»)/(СЧЁТЗ(A1:A9)+СЧИТАТЬПУСТОТЫ(A1:A9)) |
Готово.
Функция № 7: СУММЕСЛИ (диапазон;критерий;диапазон_для_сложения) (англ. SUMIF)
Принцип такой же, как и в предыдущем примере. Главное отличие: два параметра с диапазонами. Первый — для применения критерия, второй — для применения сложения значений.
Функции № 8: ЛЕВСИМВ (текст;количество знаков) (англ. (LEFT), ПРАВСИМВ (текст;количество знаков) ( англ. RIGHT)
Возвращают заданное количество знаков слева (или справа). Как правило, используются в устоявшейся связке с функцией ПОИСК.
Функция № 9: ПОИСК (искомый фрагмент, просматриваемый текст,начальная позиция) (англ. SEARCH)
Возвращает номер вхождения искомой подстроки в общую строку. Например, применение следующей формулы возвратит «2», так как буква «п» входит в слово «оптимизация» на второй позиции:
|
1 |
«]=ПОИСК («п»;»оптимизация») |
Очевидно, что само по себе знание о позиции вхождения подстроки является малополезным даже в SEO :)
В моей практике использование связки ЛЕВСИМ + ПОИСК (или ПРАВСИМВ + ПОИСК) встречалось достаточно редко. Более того, пока я пишу описания и примеры этих функций, в голове то и дело мелькает афоризм:
У вас есть проблема. Вы решили использовать регулярные выражения, чтобы её решить. Теперь у вас две проблемы.
Ведь, как известно, «нет ничего более беспомощного, безответственного и испорченного, чем сеошник, прибегнувший к функциям поиска по подстроке».
Тем не менее, рассмотрим пример: у нас есть список URL-ов, и нам необходимо выделить из них непосредственно домен.

Будем следовать такой логике: нам надо «найти» точку непосредственно на слеше после домена, после этого вырвать кусок строки слева — с нулевой точки до найденной нами точки конца домена. Разобьем задачу на подзадачи.
1.
Что ищем? Слеш. Где ищем? В ячейке с URL. С какой позиции ищем? Как минимум, с восьмой, чтобы исключить начальные слеши.
Итог:
|
1 |
«]=ПОИСК(«/»;ячейка_с_URL;8) |

2.
Выделим подстроку с доменом: с начала строки до точки вхождения слеша.
|
1 |
«]=ЛЕВСИМВ(ячейка_URL;ПОИСК(«/»;ячейка_URL;8)) |

При определенной сноровке с текстовыми функциями Excel можно творить настоящие чудеса.
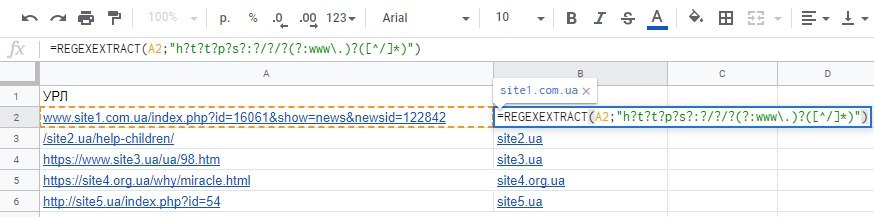
В Google Таблицах для извлечения домена из URL можно воспользоваться функцией REGEXTRACT
|
1 |
«]=REGEXEXTRACT(ячейка_URL;»h?t?t?p?s?:?/?/?(?:www\.)?([^/]*)») |
Это выражение почистит URL и оставит только доменное имя с доменной зоной:
Функция № 10: ЕСЛИ (лог_выражение; [значение_если_истина]; [значение_если_ложь]) (англ. IF)
Трудно переоценить значение этой функции в seo, особенно в связке с другими функциями. Рассмотрим задачу сегментации семантического ядра интернет-магазина ноутбуков. Предположим я хочу найти все запросы с упоминанием бренда ноутбуков “HP” (Hewlett-Packard). Если делать вручную — то придется перебирать более 1800 запросов. Для ускорения сегментирования используем функцию ЕСЛИ в связке с функциями ЕЧИСЛО (проверяет является ли значение числом) и функцию ПОИСК которую мы рассмотрели выше:
|
1 |
«]=ЕСЛИ(ЕЧИСЛО(ПОИСК(«hp»;ячейка_с_ключевым_словом));»Hewlett-Packard») |
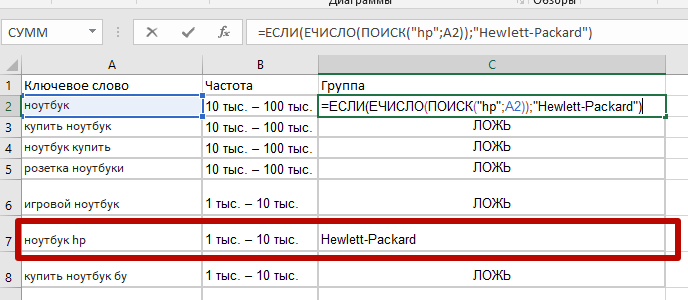
Указанная функция ищет совпадение в ячейке с текстом “hp” и если совпадение в ячейке найдено — возвращает текст “Hewlett-Packard”
Осталось применить функцию ко всему столбцу, сортировать по наименованию — и мы получим семантическую группу ноутбуков Hewlett-Packard.
Функция № 11: ВПР (искомое_значение, таблица, номер_столбца, тип_совпадения) (англ. VLOOKUP)
Кратко суть функции описать сложно, а в официальной справке приведено абсолютно непонятное объяснение. По сути, это «состыковка» значений разных таблиц на основании анализа данных в ячейках. Рассмотрим как это работает на очередном вымышленном примере. Пусть у нас будет список ссылающихся на наш сайт доменов, анкоров их ссылок, ТИЦ и PR этих сайтов.

Как мы видим, порядок сайтов в этих двух таблицах разнится. Без использования функций перенести данные из второй таблицы в первую, кроме как «руками», невозможно. Попробуем использовать функцию ВПР.
|
1 |
«]=ВПР(A2;F2:H11;2;ЛОЖЬ) |

-
Первый параметр, А2, определяет, по какому значению мы ищем совпадения. В нашем случае нам надо «состыковать» таблицу по отдельным доменам.
-
Второй параметр, F2:H11 — это таблица с «эталонами». То есть та, где мы ищем.
-
Третий параметр, 2 — номер столбца в этой «эталонной» таблице, из которого мы берем значения. Слева-направо, в случае с «ТИЦ», значение «2».
-
Четвёртый параметр (самое важное), ЛОЖЬ — тип совпадения. Здесь таится одна из самых больших сложностей этой функции.
ЛОЖЬ означает, что мы ищем точное совпадение содержимого ячейки в таблице с эталонами. ИСТИНА же означает, что, при отсутствии точного совпадения, будет использовано ближайшее к нему по убыванию. Также при использовании ИСТИНЫ рекомендую производить сортировку столбца по возрастанию, иначе результат может быть некорректным. Кстати, в том случае, если в эталонной ячейке искомая ячейка встречается несколько раз, будет использовано первое значение.

Работает! Растянем формулу на весь столбец и дело в шляпе? Нет. Мы задали адрес таблицы как относительный, то есть при растягивании формулы фокус с эталонной таблицы будет смещаться вниз на пустые ячейки. Чтобы это исправить, используем:
|
1 |
«]=ВПР(A2;$F$2:$H$11;2;ЛОЖЬ) |

Работает. Теперь для соседнего столбца:

Функция № 12: Поиск дубликатов.
Перед SEO-специалистом часто появляется задача — найти дубликаты данных. Это могут быть одинаковые title или h1, одинаковые домены в списке доноров и т.д.
Чтобы быстро найти дубли, выделим массив данных и воспользуемся условным форматированием
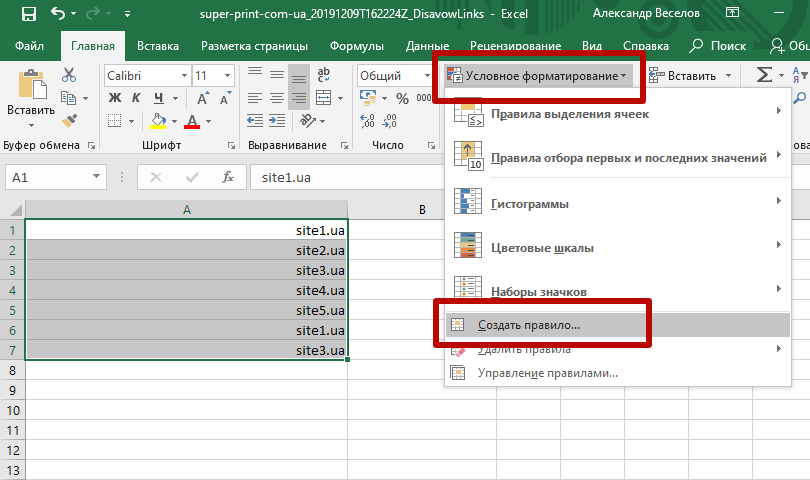
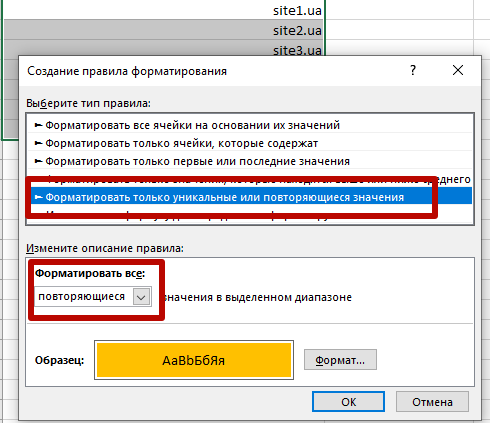
В результате наши дубликаты подсвечиваются заданным цветом
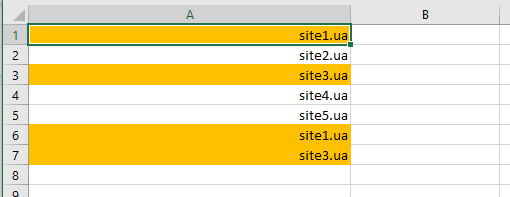
применив сортировку по цвету, мы получим наши дубликаты в удобной для работы форме:
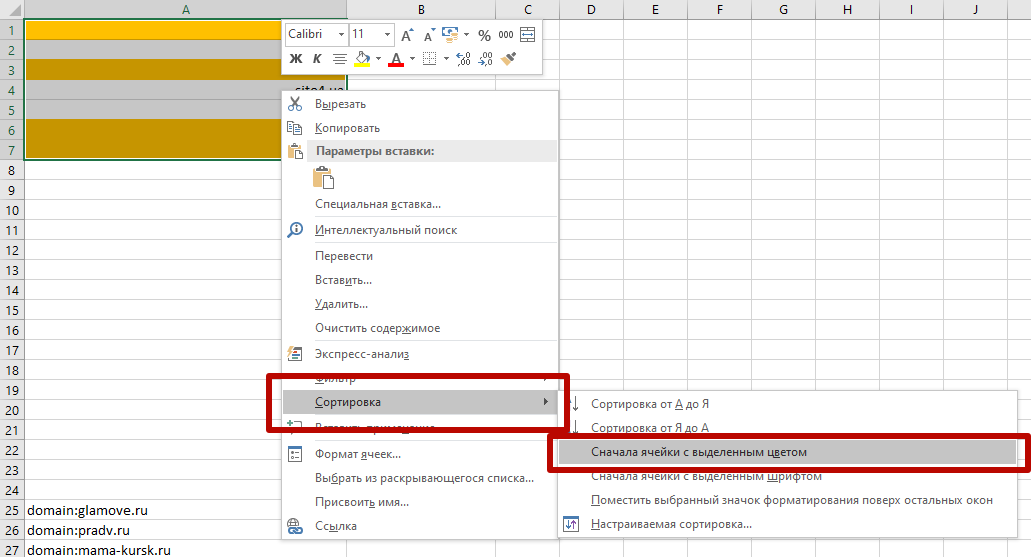
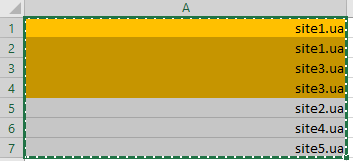
К сожалению в Google Spreadsheets нет заложенной функции форматирования дубликатов по цвету, однако её легко заменить формулой
|
1 |
«]=СЧЁТЕСЛИ(определяемый_диапазон;значение)>1 |
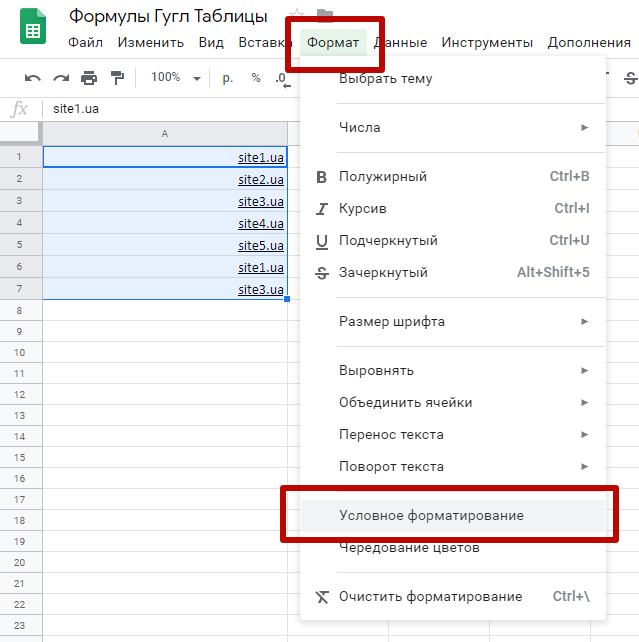
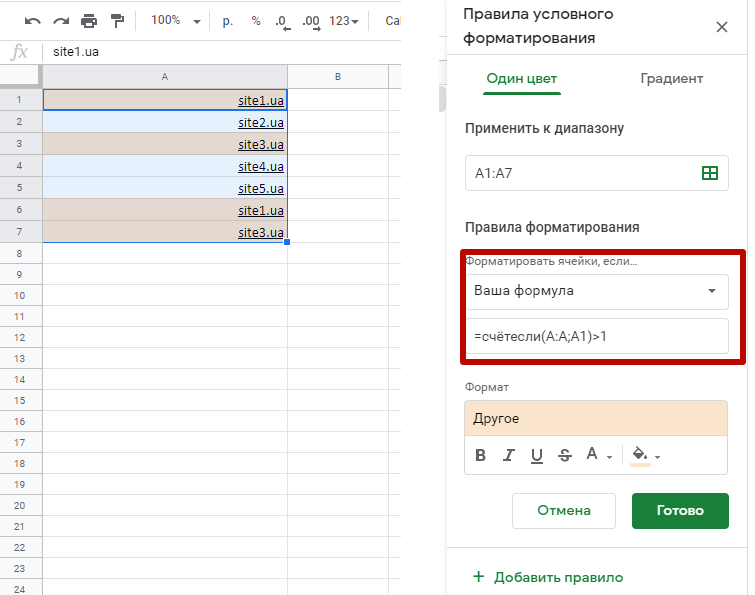
[ниже текст перенес с предыдущего пункта]
А теперь перейдём непосредственно к встроенному функционалу программы MS Excel.
Здесь безусловными лидерами по полезности для SEO-специалиста являются 2 функции: очистка от дублей и разбитие данных по столбцам по разделителю.
Функция № 13: Данные > Удаление дубликатов (Data > Remove Duplicates)
Позволяет быстро очистить список от всех дублей, не заморачиваясь с их поиском.
Допустим, у нас есть список доменов на 1200 строк. Как вариант можно попробовать найти и убрать дубли «руками», можно отсортировать список по алфавиту и удалить «руками» с уже намного меньшими усилиями, использовать макрос для Excel, использовать софт по работе с ключевыми словами (по умолчанию удаляет дубли), использовать паблик-скрипты или онлайн-сервисы. Понятно, что если количество строк большое (например, более 1 048 576 строк для Excel), вариант со специализированным софтом или скриптами является единственно возможным. Но если строк меньше граничного максимума, Excel работает на ура.
Итак, на старте имеем 1266 доменов + aweb.ua:
![]()
Кликаем на шапке столбца, чтобы выделить его целиком (как вариант — тянем выделение руками или, кликнув на первой ячейке с содержимым, нажимаем Ctrl+A). Весь наш список должен быть выделен.
Переходим во вкладку «Данные» и находим пункт меню «Удалить дубликаты».


Кликаем «Ок».

То же самое можно сделать и с помощью абсолютно бесплатного инструмента Google Таблицы.
Есть несколько вариантов удаления дубликатов:
Вариант 1. Открыть меню “Данные” и нажать кнопку “Удалить дубликаты”
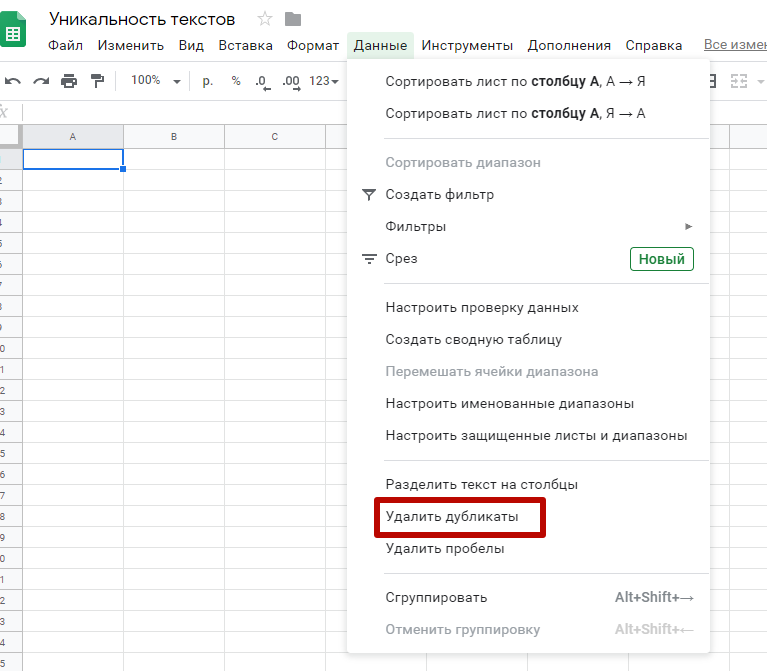
Вариант 2. Для удаления дублей используем функцию:
|
1 |
«]= UNIQUE (массив) |
Так как массив данных у нас лежит в столбце A, в ячейку соседнего столбца вставим формулу:
|
1 |
«]=UNIQUE(A1:A841) |
Готово. В столбец B автоматически зальётся массив уникальных строк. Формулу растягивать не надо, всё реализовано через функцию CONTINUE.
Функция № 12: Данные > Текст по столбцам (Data > Text to Columns)
Крайне полезная функция, которая позволяет разбивать различные массивы на составляющие по отдельным столбцам. Также позволяет задать любой разделитель на ваш выбор (слеш, точку, запятую и т.п.). Например, мы можем без использования регулярных выражений и функций поиска по строке легко и быстро извлечь домены из списка различных URL.
Допустим, у нас есть массив данных с разделителем вида «пайп» (вертикальная черта).

Выделяем наш массив данных. Находим во вкладке «Данные» пункт «Текст по столбцам». Кликаем, предварительно выделив нужный нам массив данных. Появляется «Мастер распределения текстов по столбцам»


Жмём «Далее». На втором шаге отмечаем тип разделителя «Другой» и вставляем туда символ вертикальной черты.

На следующем шаге не забудьте выставить значение в поле «Поместить в», иначе столбец с данными перезапишется (хотя в 99% случаев именно это нам и нужно).

Готово! Несмотря на всю кажущуюся простоту, разбивка на столбцы по заданному разделителю является одной из наиболее часто используемых и полезных SEO-функций программы.
На этом всё. В дальнейшем я планирую написать большую статью по использованию сводных таблиц Excel в SEO — тема не менее интересная и объемная, чем затронутая сегодня. А пока надеюсь, что данный материал спасёт не один десяток веб-мастеров от бессмысленной траты времени на рутинные задачи и не только откроет для вас дружественный мир Excel, но и вдохновит на дальнейшие поиски решений по автоматизации работы.
Теперь ваша очередь, друзья — как вы справляетесь со своей SEO-рутиной?




